nonmpi_t0000.png
mpi_t0000.png
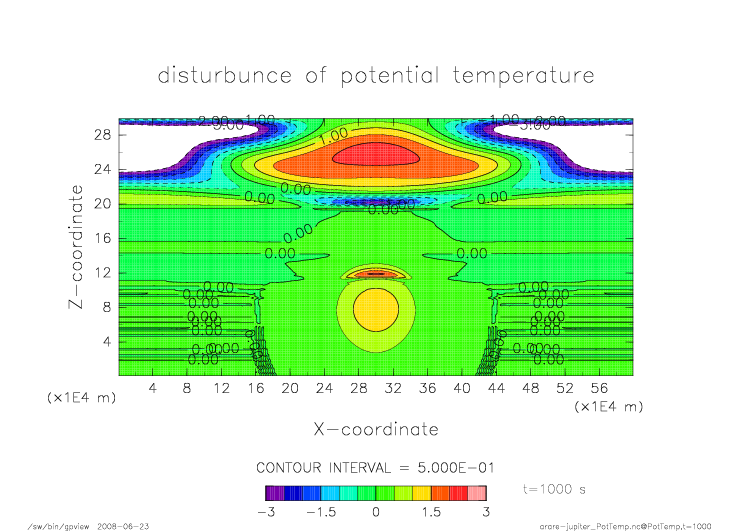
nonmpi_t1000.png
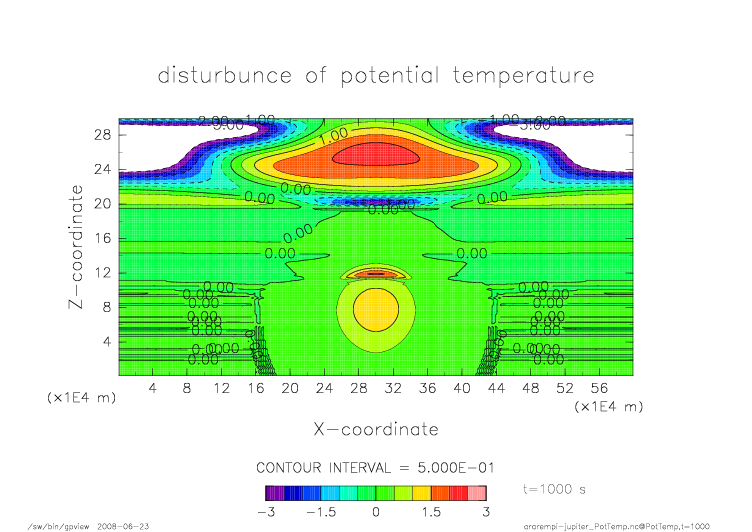
mpi_t1000.png
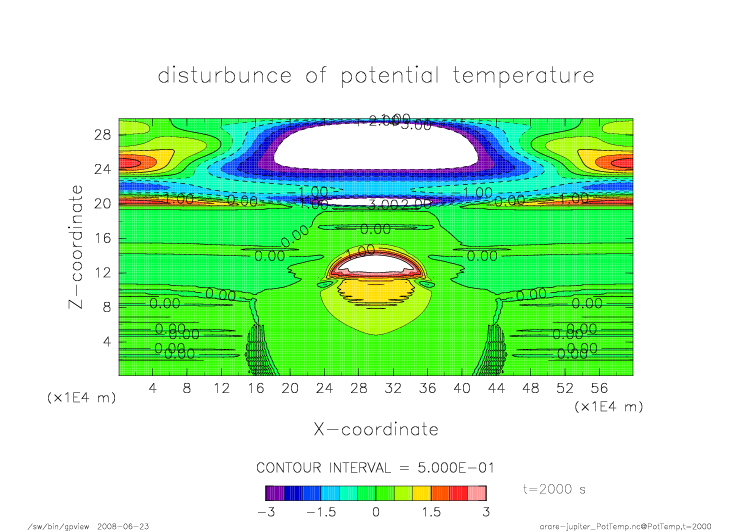
nonmpi_t2000.png
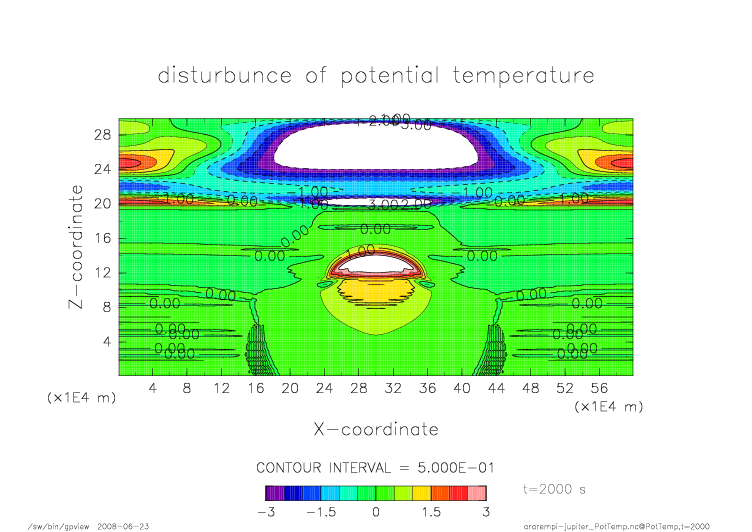
mpi_t2000.png
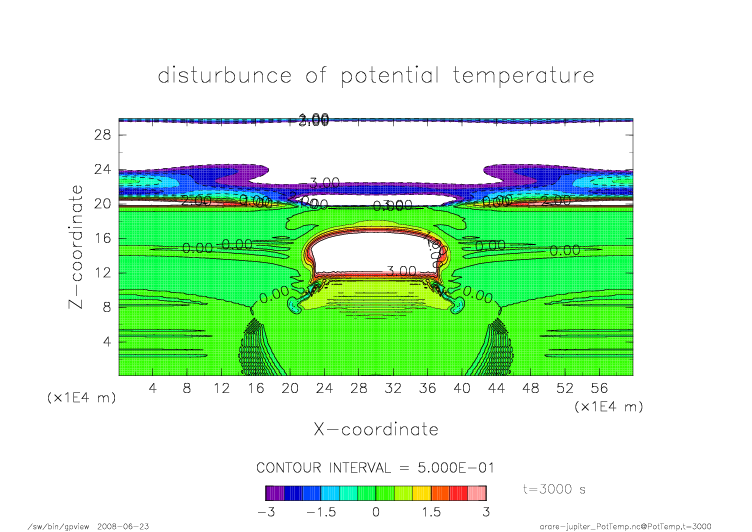
nonmpi_t3000.png
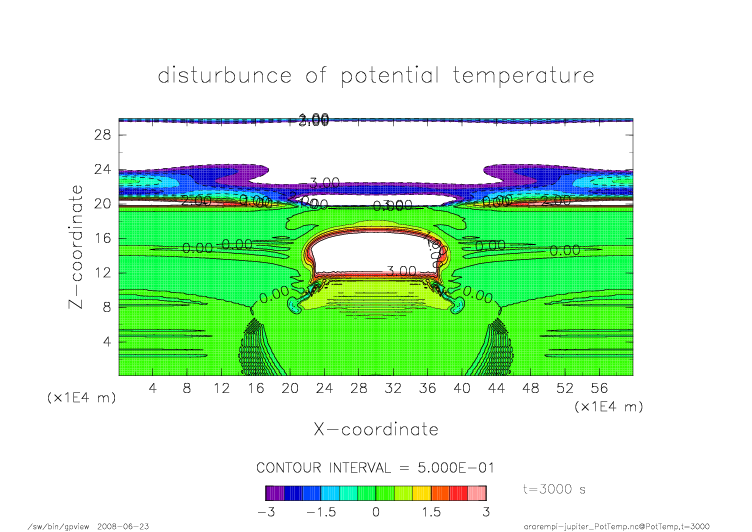
mpi_t3000.png
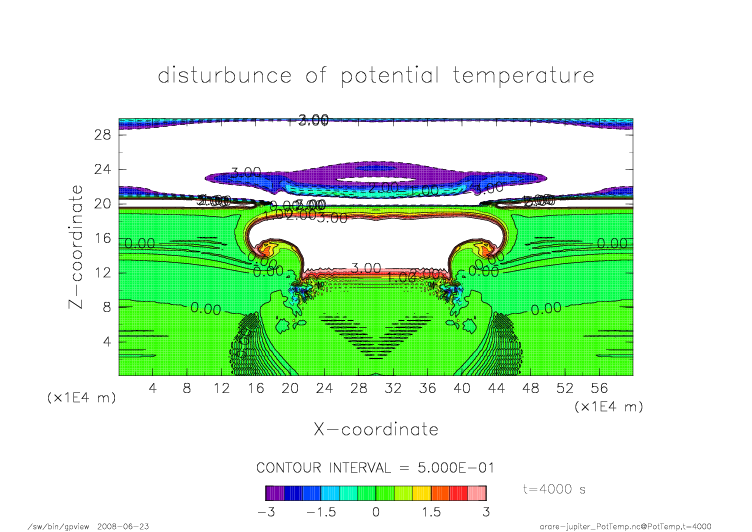
nonmpi_t4000.png
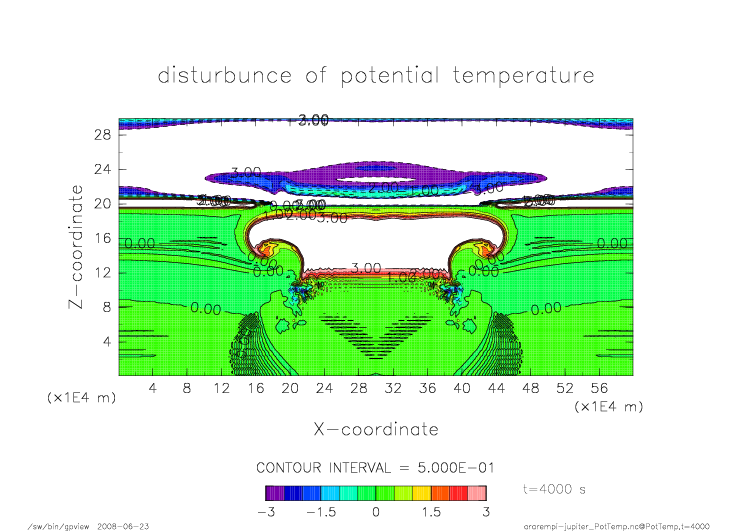
mpi_t4000.png
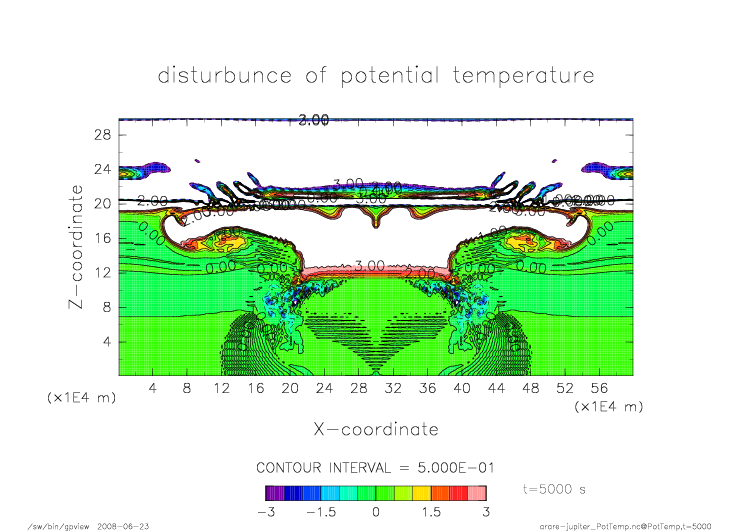
nonmpi_t5000.png
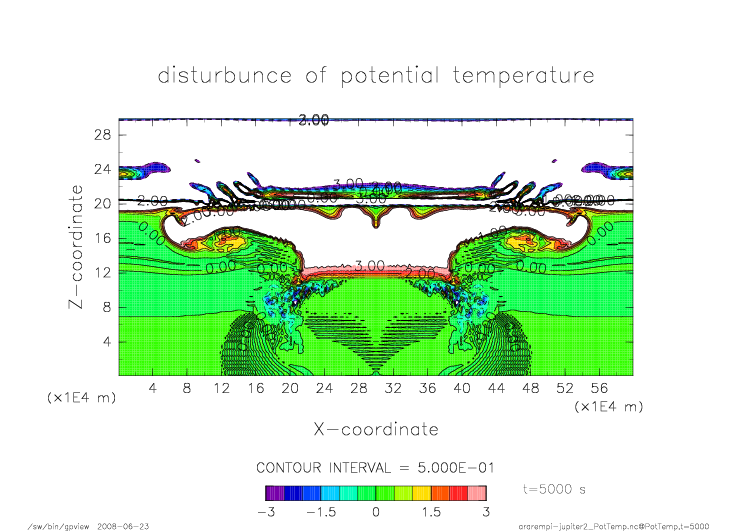
mpi_t5000.png
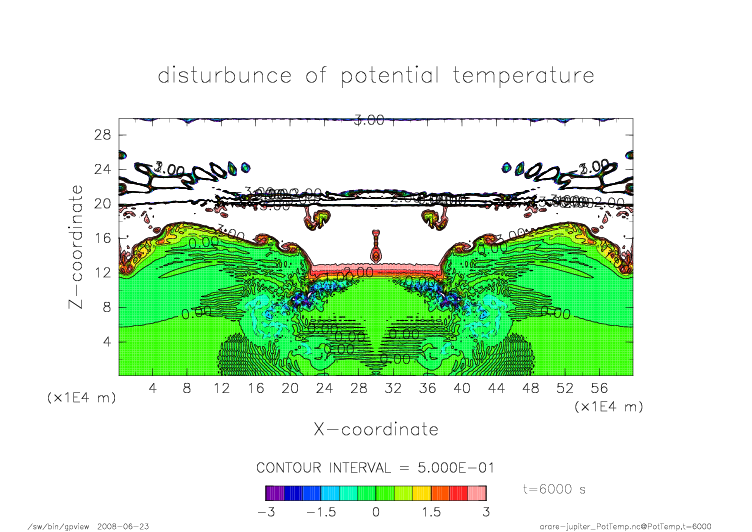
nonmpi_t6000.png
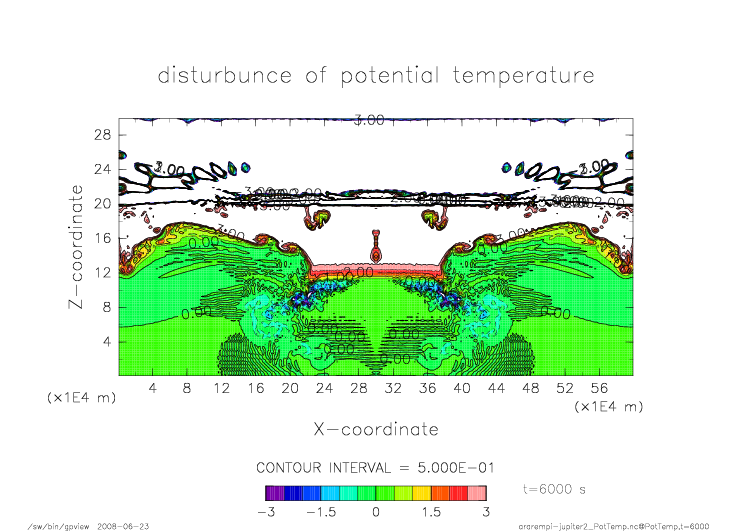
mpi_t6000.png